# 线程的概念
说实话即使是现在我对线程也不能说完全懂了。进程时系统资源分配的最小单位,线程时 cpu 操作和调度的最小单位,本质是一组寄存器的状态,是操作系统对寄存器状态的抽象。XV6 每个进程只有一个页内存用于栈,也就是每个线程只对应一个线程。所以线程的切换等价于进程的切换。在 xv6 中所有的内核进程是共享内存的,而用户进程是完全内存隔离的。进程的切换和之前 trap 很类似,但是不同的是 trap 结束后返回的是同一个进程,而 switch 要切换到另一个进程。
内核进程和用户进程到底什么关系我之前也思考了很久,我想对 CPU 来说用户进程和内核进程或许差不多,它们都是相同的 pid,拥有差不多的 proc 数据结构。但是对于内核进程和用户进程来说,这完全不一样,他们有着不同的权限,不同的数据结构,不同的内存空间。因为 trap 会切换 stap 寄存器,这会导致整个内存地址空间发生了改变, whole world changed 。但是它们又是运行在相同的 CPU 上。
对于进程的切换与 trap 最大的不同在于,用户进程进入内核空间后才能进行进程切换,这就需要再保存当前内核线程的 context,然后切换到 scheduler 线程,由 scheduler 线程再切换到另一个 Runable 的线程。然后再返回用户空间实现了用户线程之间的切换。

linux 中的多线程可以实现一个用户进程多个线程,这些线程共享进程的内存。但是这里的多线程可以认为多个进程但是这些进程共享同样的内存,可以是使用相同的页表,或者页表指向的 pa 相同。但是不管怎么,线程的切换不能在用户态进行,必须走到内核态,然后内核态切换到 scheduler 线程,scheduler 再切换到 Runable 的线程。因此这里并没有保证同一个进程的线程一定会运行在不同的 CPU 上?
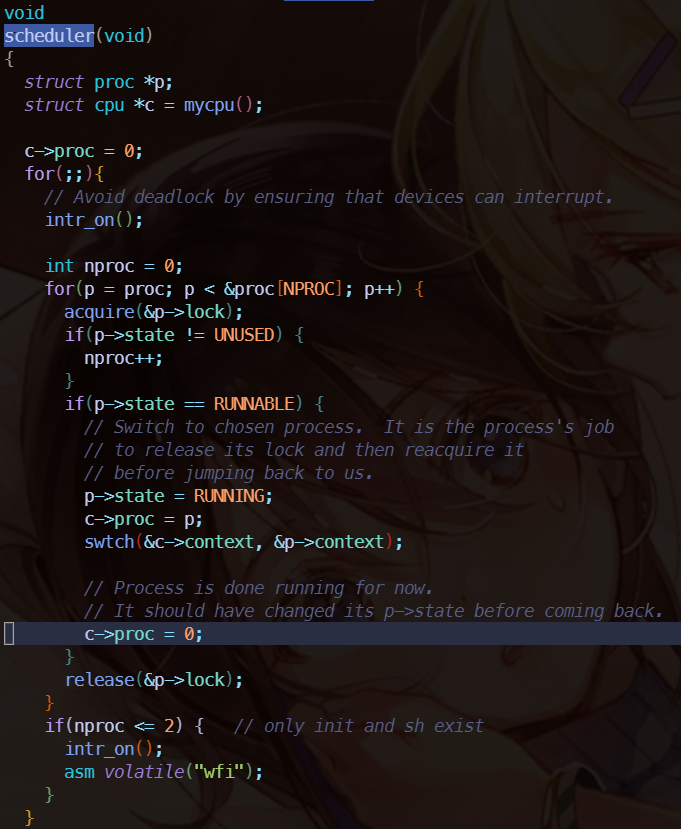
# Scheduler(时钟中断)
首先看 usertrap ,这里面有这样代码,如果判断是时钟中断会执行放弃 CPU 命令。

进入 yield 函数中,yield 先进行加锁,然后设置当前进程从 RUNNING 为 RUNNABLE。加锁的作用是防止其他 CPU 核调用该进程,因为此时的进程虽然声明了不在运行但实际上还是运行的。
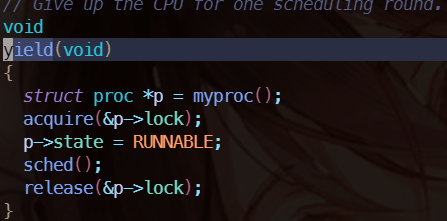
继续进入 sched 中,忽略正确性检查的代码, swtch 是核心所在,swtch 会保存当前线程的 context,然后把 scheduler 的 context 给 load,注意 scheduler 的 context 是直接保存在 cpu 上的,因为我们调度肯定是 CPU 来完成。
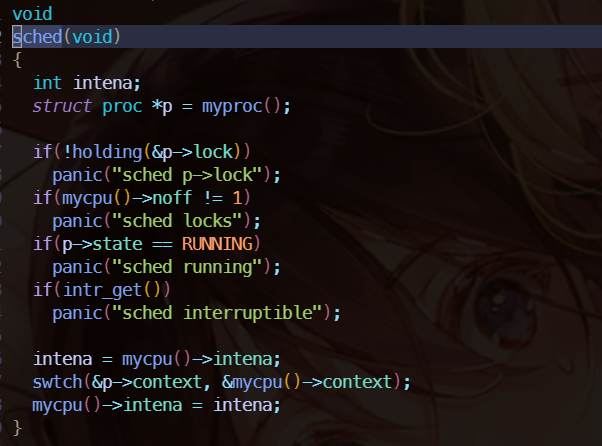
swtch 函数,只保存了 ra、sp 和 callee registers。因为 swtch 相当于一个函数调用,我们使用函数调用的处理方式来处理,把编译器没有保存的寄存器给保存就行了。
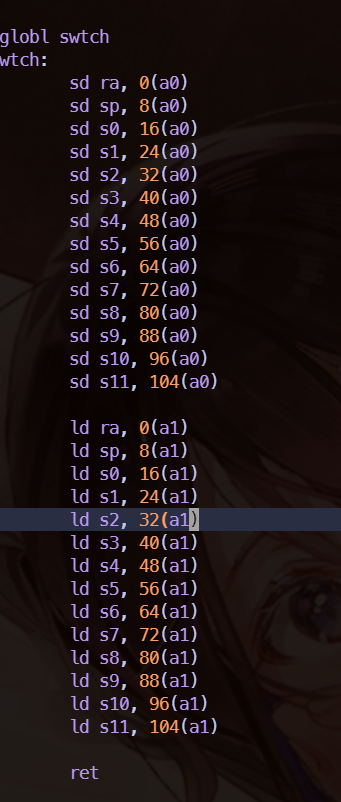
scheduler 函数,我们可以看到 swtch 函数返回了,scheduler 继续执行,找到下一个 runnable 的 proc,然后执行 switch 操作。时刻记住 swtch 就相当于一个函数调用。因为内核的进程共享内存,使用相同的页表。不同的是不同的进程有不同的内核栈。