先开个坑,把 docker 容器虚拟化给学一下。
docker 其实我一直都想好好学一下,之前只是简单地略了一次,这次趁着寒假,把容器和 CI 这块好好搞一下。
so,start dash!
# What is docker?
docker 是一种虚拟化技术,和虚拟机不同的是,docker 是直接运行在操作系统内核上的用户控件。容器技术可以让多个独立的用户空间运行在一台宿主机。

容器提供了在计算机上的隔离环境中安装和运行应用程序的方法。在容器内运行的应用程序仅可使用于为该容器分配的资源,例如:CPU,内存,磁盘,进程空间,用户,网络,卷等。在使用有限的容器资源的同时,并不与其他容器冲突。您可以将容器视为简易计算机上运行应用程序的隔离沙箱。
说白了,就是 linux 划分出一个隔离的空间,这个空间有内存有计算资源。
Docker 技术使用 Linux 内核和内核功能(例如 Cgroups 和 namespaces)来分隔进程,以便各进程相互独立运行。这种独立性正是采用容器的目的所在;它可以独立运行多种进程、多个应用,更加充分地发挥基础设施的作用,同时保持各个独立系统的安全性。
容器通过 Namespace 进行资源隔离,通过 Cgroup 进行资源控制,通过 rootfs 进行文件系统隔离,容器引擎自身的特性来管理容器的生命周期。
# Namespace 进行资源隔离
chroot 命令: change root directory(更改 root 目录),因为系统默认目录结构是以 / 开始的,即 root 目录就是 / ,修改 root 目录之后,系统会通过指定的位置作为 / 。比如我用 chroot target /bin/sh 。
chroot 实现的就是一种隔离。
Namespace 的作用之一:实现轻量级的虚拟化服务。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响
我们可以从 docker 实现者的角度考虑该如何实现一个资源隔离的容器。比如是不是可以通过 chroot 命令切换根目录的挂载点,从而隔离文件系统。为了在分布式的环境下进行通信和定位,容器必须要有独立的 IP、端口和路由等,这就需要对网络进行隔离。同时容器还需要一个独立的主机名以便在网络中标识自己。接下来还需要进程间的通信、用户权限等的隔离。最后,运行在容器中的应用需要有进程号 (PID),自然也需要与宿主机中的 PID 进行隔离。也就是说这六种隔离能力是实现一个容器的基础,让我们看看 linux 内核的 namespace 特性为我们提供了什么样的隔离能力:

容器需要的六种 namespace。
# 进行 namespace API 操作
# clone
clone 就是加强版的 vfork,因为 vfork 调用生成的子进程实际上是和父进程共享内存地址空间的,而 clone 就可自定义需要共享的是啥。
int clone (int (*child_func)(void *), void *child_stack,int flags, void *args)
flag 参数可以对 namespace 进行操作。
# /proc/[pid]/ns

$$ 指当前进程
可以看到这些文件实际上都是软连接,指向 namespace 文件的 inode。
mount --bind /proc/$$/ns/uts ~/uts
就是用 ~/uts 来作为一个新的软连接。
# setns
setns 可以是进程加入到新的 namespace。
int setns(int fd, int nstype)
fd 是 namespace 的文件描述符, nstype 指定是否需要检查 namespace 类型是否符合实际要求。
fd = open(argv[1], O_RDONLY); | |
setns(fd, 0); // 调用 setns | |
execvp(argv[2], &argv[2]); // 执行命令 |
./setns ~/uts /bin/bash
setns 执行后会执行 clone 创建子进程,而原来的父进程会终止。
# UTS namespace
uts 是域名和主机名的隔离,容器和主机应该具有不同的 hostname 。
代码:
#define _GNU_SOURCE | |
#include<sys/types.h> | |
#include<sys/wait.h> | |
#include<stdio.h> | |
#include<sched.h> | |
#include<signal.h> | |
#include<unistd.h> | |
#define STACK_SIZE (1024*1024) | |
static char child_stack[STACK_SIZE]; | |
char* const child_args[] = { | |
"/bin/bash", | |
NULL | |
}; | |
int child_main(void* args){ | |
printf("在子进程中!\n"); | |
sethostname("NewNamespce", 12); | |
execv(child_args[0],child_args); | |
return 1; | |
} | |
int main(){ | |
printf("------begin----------\n"); | |
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUTS| SIGCHLD, NULL); // 这里设置了 CLONE_NEWUTS,表示子进程克隆了父进程的 uts。 | |
waitpid(child_pid, NULL, 0); | |
printf("------end------------\n"); | |
return 0; | |
} |

可以看到新的进程内,hostname 发生了改变,我说当时用 docker 的时候,怎么 hostname 是一串奇奇怪怪的数字。
现在明白了,这就是 uts 隔离。
# IPC 隔离
IPC 隔离就是进程间通信隔离。因为进程间通信有多种,有消息队列,共享内存、管道等方式。所以 IPC 隔离的作用的就是 docker 内的进程使用容器内的消息队列和共享内存等等,IPC namespace 下的进程彼此可以通信,不同 IPC namespace 进程不能通信。
IPC 可以看👉 PIC:进程间通信
修改语句: int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUTS| SIGCHLD, NULL);
ipcmk -Q : 创建 ipc 消息队列
ipcs -q : 查看消息队列

可以看到 ipc namespace 发生了隔离。
# PID 隔离
pid 就是 process id 进程 id。 pid 隔离就是不同 pid namespace 可以允许有相同的 pid。
Linux 会维护一个 pid namespace 树,最顶层的 root 节点是系统初始化时创建的,原先的 pid namespace 是新创建的 pid namespace 的父节点。子节点不能看到父节点的进程,但父节点可以看到子节点。
pid 1 是 init 进程,通常为 bash 或 zsh 等 sh 。init 进程负责回收所有的孤儿进程(发生错误导致没有父进程)。父节点 pid namespace 的进程可以强行杀死子节点 pid namespace 节点的 init 进程,一旦 init 进程被杀死,该 pid namespace 下的所有进程都会被终止。
问题:子节点仍然可以看到父节点进程。

解决:重新挂载 proc mount -t proc proc /proc

对于进程来说 pid namespace 应该是一个常量。
# mount 隔离
挂载隔离就是隔离文件系统挂载点实现对隔离文件系统支持。
挂载传播:共享挂载、私有挂载。
挂载:
指的就是将设备文件中的顶级目录连接到 Linux 根目录下的某一目录(最好是空目录),访问此目录就等同于访问设备文件。
Linux 系统中 “一切皆文件”,所有文件都放置在以根目录为树根的树形目录结构中。在 inux 看来,任何硬件设备也都是文件,它们各有自己的一套文件系统(文件目录结构)。
因此产生的问题是,当在 Linux 系统中使用这些硬件设备时,只有将 Linux 本身的文件目录与硬件设备的文件目录合二为一,硬件设备才能为我们所用。合二为一的过程称为 “挂载”。
这里 Unix 目录结构来历值得一看。
这里真有点脑子不够用的感觉。。。
# mount 文件 or 目录绑定
这里有一篇好文章 mount 命令进阶
sudo mount --bind [DirFile-1] [DirFile-2]
sudo umount [DirFile-2]
解绑用绝对路径。
bind 不会增加 inode 的引用次数
# network 隔离
进行网络资源的隔离。
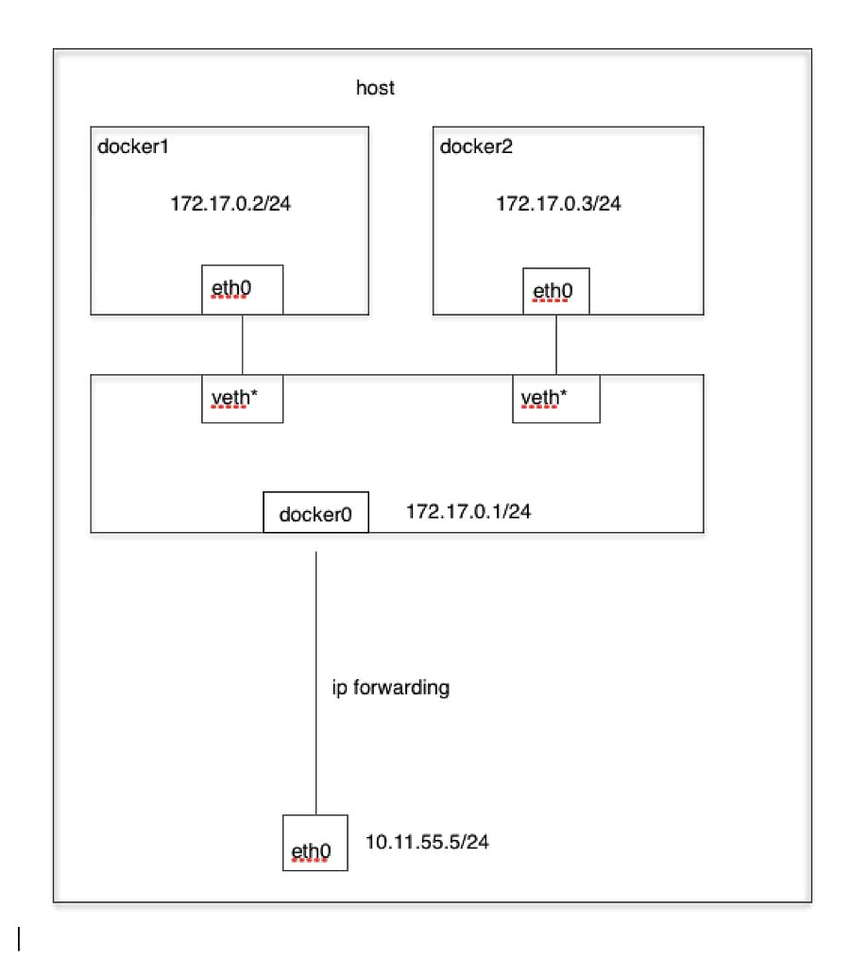
docker 可以实现网络隔离,这部分之后再细看。
这里有一篇博客,写的很好一分钟看懂 Docker 的网络模式和跨主机通信
# user 隔离
通过映射可以将 container 内的用户映射为外部用户,这样就具有了外部用户的权限
# Cgroup
待填坑