# 代码阅读
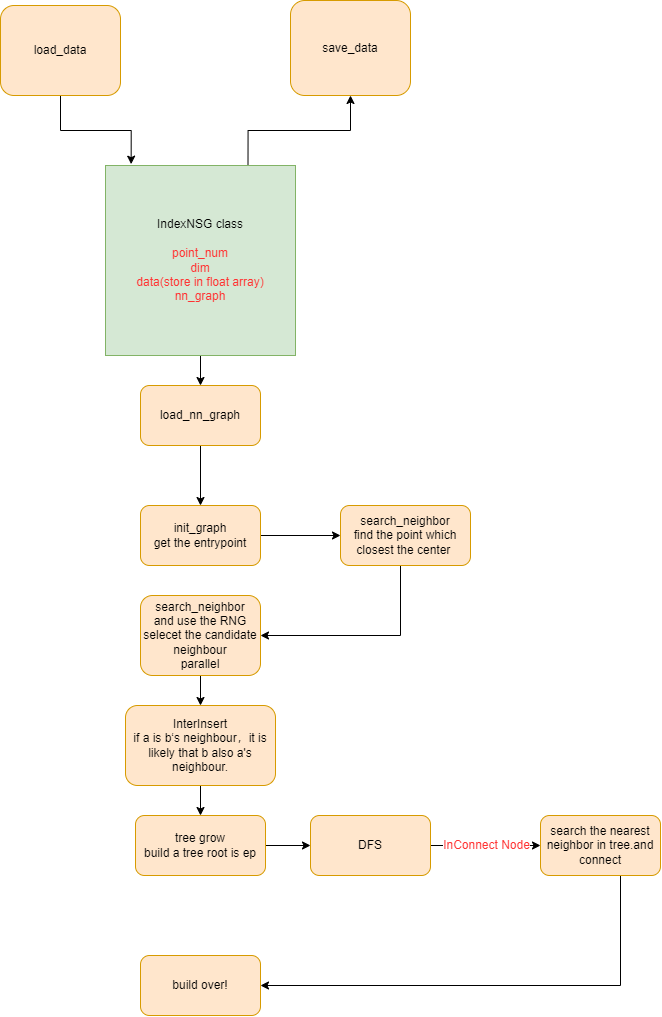
把 Index 部分读完了,挺有意思的。做了个 Index 流程图:
NSG 的代码 search 做了一些非常有意思的优化,但是它们的论文中却没有提到。
1)对于每个 point,把它的全精度向量和它的邻居存放在一起。这样可以尽可能保证局部性。
2)使用 _mm_prefetch 进行预取数据
_mm_prefetch(opt_graph_ + node_size * id, _MM_HINT_T0); //fetch 到所有缓存级别中 |
_mm_prefetch 代码的作用其实很简单,就是把当前地址的数据 fetch 到特定的缓存级别中,fetch 的数据大小是 cache line 。 _MM_HINT_T0 表示加载到全部缓存级别。
# search 算法实现
记录一下 search 算法的实现
void IndexNSG::get_neighbors(const float *query, const Parameters ¶meter, | |
std::vector<Neighbor> &retset, | |
std::vector<Neighbor> &fullset) { | |
unsigned L = parameter.Get<unsigned>("L"); | |
retset.resize(L + 1); | |
std::vector<unsigned> init_ids(L); | |
// initializer_->Search(query, nullptr, L, parameter, init_ids.data()); | |
boost::dynamic_bitset<> flags{nd_, 0}; | |
L = 0; | |
for (unsigned i = 0; i < init_ids.size() && i < final_graph_[ep_].size(); | |
i++) { | |
init_ids[i] = final_graph_[ep_][i]; //init 阶段会 rand 一个 ep_ | |
flags[init_ids[i]] = true; | |
L++; | |
} | |
while ( | |
L < | |
init_ids.size()) { // 如果不够 L 就随机加上几个 point,直到 candidate 池到达 L | |
unsigned id = rand() % nd_; | |
if (flags[id]) | |
continue; | |
init_ids[L] = id; | |
L++; | |
flags[id] = true; | |
} | |
L = 0; | |
for (unsigned i = 0; i < init_ids.size(); i++) { | |
unsigned id = init_ids[i]; | |
if (id >= nd_) | |
continue; // 这个判断条件意义? | |
// std::cout<<id<<std::endl; | |
float dist = distance_->compare(data_ + dimension_ * (size_t)id, query, | |
(unsigned)dimension_); // 得到 distance | |
retset[i] = Neighbor(id, dist, true); | |
// flags[id] = 1; | |
L++; | |
} | |
std::sort(retset.begin(), retset.begin() + L); | |
int k = 0; | |
// 不得不吐槽啊,这代码写得真混乱 | |
while (k < (int)L) { | |
int nk = L; | |
if (retset[k].flag) { // 防止回溯 | |
retset[k].flag = false; | |
unsigned n = retset[k].id; | |
for (unsigned m = 0; m < final_graph_[n].size(); ++m) { | |
unsigned id = final_graph_[n][m]; | |
if (flags[id]) | |
continue; | |
flags[id] = 1; | |
float dist = distance_->compare(query, data_ + dimension_ * (size_t)id, | |
(unsigned)dimension_); | |
Neighbor nn(id, dist, true); | |
fullset.push_back(nn); | |
if (dist >= retset[L - 1].distance) | |
continue; | |
int r = InsertIntoPool(retset.data(), L, nn); | |
if (L + 1 < retset.size()) | |
++L; | |
if (r < nk) | |
nk = r; | |
} | |
} | |
if (nk <= k) // 说明新插入的那个 point 比当前的 point 离 query 更加进。 | |
k = nk; | |
else | |
++k; | |
} | |
} |
# 总结
NSG 代码是我第一次看的代码,实现的很精妙。一开始自己完全不懂 SIMD 和 OMP 的相关知识,看得很痛苦。。。补了些相关知识后,终于花了一天把这个实现读完了。