这篇文章主要是过一下 KGraph,也就是 NN-Descent 算法,A Comprehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search。
NN-Descent 实际上就是一个近似 K-NNG 的构建方法。
# 作者的动机
高效的 K-NNG 构建方法一直是一个公开的问题,然而没有哪个方法能够做到通用、高效以及可扩展性,作者希望能够解决这些问题。
通用:对于任意的 similarity oracle,该方法都能适用。
可扩展性:也就是 dataset 可以不断正常,满足 online 场景。
高效、准确、易于实现。
# 算法拆解
# 原始算法

这个算法的核心就是一句话 —— 邻居的邻居有可能是邻居。
B 列表存的是节点的 K 近邻,R 列表存以节点为 K 近邻的节点。因此 B[v] \or R[v] 得到新的数据 ,然后我们说,邻居的邻居也有可能是邻居:

这个算法的停止条件就是没法优化了,也就是邻居的邻居经过分析都没有可能互相成为邻居。
# 优化后的算法

作者做一下优化:
1)对于 u1,u2 两个点,他们实际上会比较两次,因此加上限定条件 u1 < u2。
2)local join,不是更新 v,而是更新 u1 和 u2.
3)加入 sample 操作。
4)使用 old 和 new 两个数组。
5)早停。
# 理解这里的条件
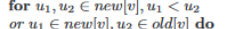
B [v] 初始化或者插入一个新值的时候,都会把 flag 设为 true。因为我们是 local join,通过一个中间点把两边邻居的 B 进行更新。所以对于自己的 B [v] 的值来说,flag 为 true 说明还没有处理这些加入的点。因此如果 u1,u2 都属于 new 中,那么我们满足 u1<u2,防止算两遍。处理完毕后会将 flag 设置为 false,这里在 sample 的时候就设置为 false 了。
对于 old 来说,如果两个都是 old,那么说明它们之前相互比较过了,所以不必要比较。但是如果两个点,一个属于 old,一个属于 new,那么它们之前一定没有比较!