# lock-free wait-free 以及 CAS
读这篇文章需要一点关于 wait-free、lock-free 和 CAS 的前置知识。
知乎有一篇文章写了关于 wait-free 和 lock-free 的理解:对 wait-free 和 lock-free 的理解 - 我的猪猪呢的文章 - 知乎 https://zhuanlan.zhihu.com/p/342921323
对于有锁算法:

可以看到在 slip3 没有任何线程 MakeProgress 。这就是因为 T2 在 slip2 加了锁,然后可能因为 IO 操作,它在 slips 不再占用 CPU,但由于操作还没有完成,因此 T2 并没有释放锁,导致 T1 和 T3 在 slip3 没有申请到锁也就没有执行。
lock-free:
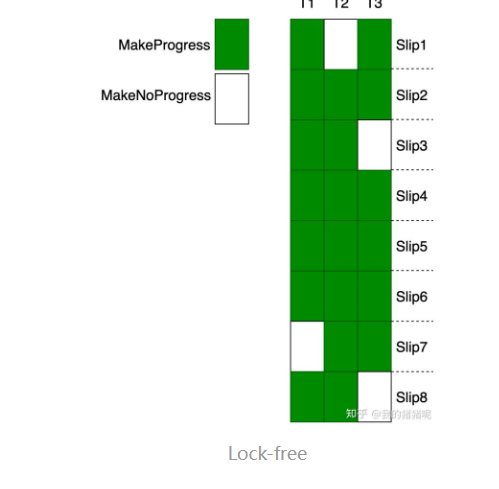
可以保证每个 slip 都能有线程 MakeProgress。这个怎么实现呢?可以通过 CAS(Compare And Swap)。
CAS 有三个操作参数:
- 内存位置 V
- 上一次从内存中读到的值 A
- 新的值 B
CAS 的操作过程:将内存位置 V 的值与 A 进行比较,如果相等说明没有其他线程来修改这个值,于是把内存 V 的值更新为 B(swap),如果不相等,说明 V 上的值被修改过了。于是程序回到开始,继续执行比较置换操作。直到成功结束 loop。因此任意时间内,总有进程能够 MakeProgress,而且时间足够长的话所有进程都能执行完。
而 wait-free 能提供更高的保证:

任意的一个 slip 下,每条线程都能够 MakeProgress。
Wait-free 被定义为算法在完成最终目标之前,每一个操作都能在有限步内实现。这里的第一个 operation 可以理解为本文的 Make Progress,step 可以理解为 Slip,当线程的每一个 Slip 都在 Make Progress 时,那么针对一个特定的算法就一定能在有限个 Slip 内完成,这是显而易见的。
# 简介
Zookeeper,a service for coordinating processes of distributed applications.
说白了就是一个协调处理分布式 process 的服务。
# The ZooKeeper service
# Znode
znode 就类似与文件系统,每个节点都是一个 zonde,每个 znode 能可能有 parent 或者 children。

# watch
当 client issue 一个 watch flag 给一个读操作。那么当这个读取的信息发生了改变的时候,就会触发 watch 给这个 client 发送一个 notification。因为我们并不需要告知 client,而只要告知发生了 change 这个事实,因此在一个时间段 change 了什么,发生了几次 change 都不需要考虑。
值得注意的是,watch 操作是一次性的,执行完通知 watch 就结束了,client 的下一次读可以接着加上一个 watch flag。
同时,如果当前 replicas 宕机了,client 会转向另一个 replicas,之前所有注册的 watch 都失效,因为 watch table 丢失了。
这里有一篇文章详细介绍了 zookeeper 的 watch:https://lvqiushi.github.io/2020/01/22/zookeeper-2/
这张图也写的很好:
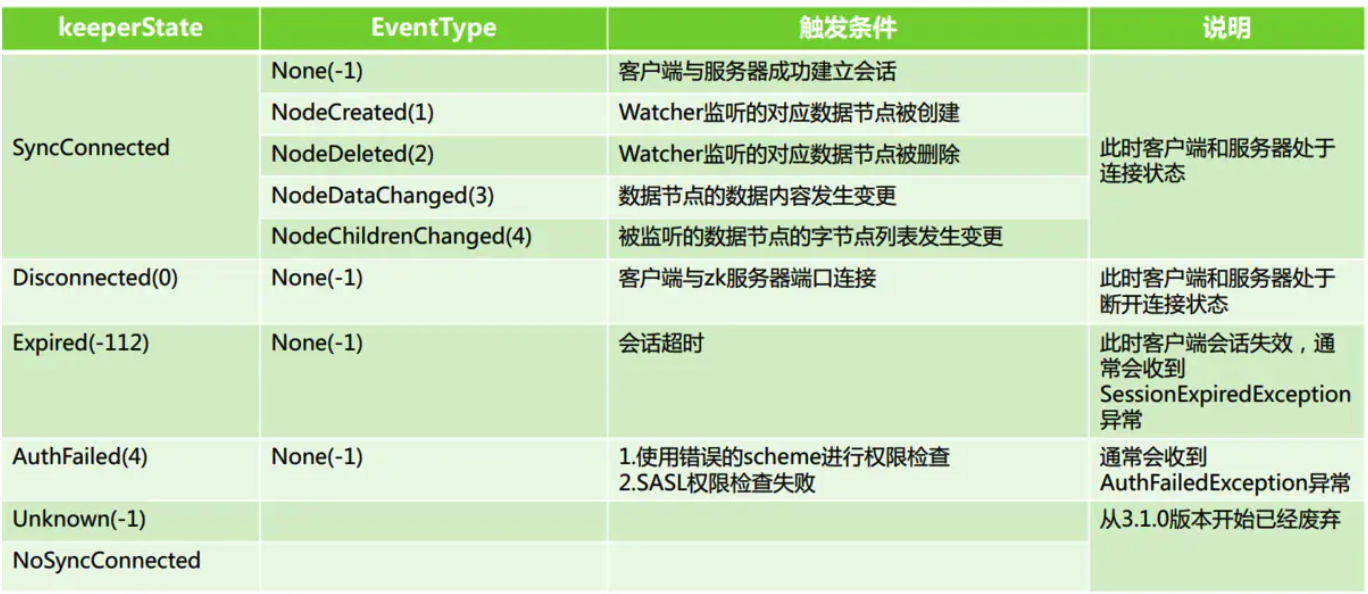
当非 None 事件出现时就会触发 watch,并且 watch 会失效。
# ZooKeeper guarantees
zookeeper 有两个基本的 ordering guarantee:
Linearizable write :zookeeper 保证所有关于 update(也就是写)的 request 都是 serializabel。(注意它并不包括读)
FIFO client order :来自一个 client 所有的 request 执行顺序遵从 client 发送这些 request 的顺序,也就是 FIFO。
# 关于 configuration
zookeeper 使用 leader/worker 机制,这就意味着当 leader 改变的时候,有大量的 configuration 参数也需要改变。但是必须满足:
- 当 leader 开始对 configuration make change,其他 processes 不应该使用这些已经改变的 configuration。
- 如果 leader 在 configuration 整个 update 完了之前就 dead 了,我们不希望这个 partial configuration 被使用。
对于第一个要求,可以使用分布式锁来控制,即 leader 写的时候其他 worker 不应该读。但是分布式锁可能导致性能下降,所以 zookeeper 提出了一个 ready znode 机制。
leader 会创建一个 ready znode,并且其他 process 都只能通过读这个 znode 来更新 configuration。如果这个 leader 需要更新 configuration,就把 ready 删除、更新数据并且创建 ready。需要注意的 ready 并不是只有一个,论文中提到可能需要 update 5000 个不同的 znode。
但是论文中也提到了一个问题,如果一个 client 读到了 ready exist,但是 new leader 在此之后对 ready 进行了 change,那么 client 就会在 change in progress 时候读到数据。
解决办法:设置 watch flag。zookeeper 可以保证在 make change 之后,在 client 读到新的数据之前一定能够收到 notification。
# Sync
sync 类似于 Flush 命令,注意 ZooKeeper guarantees,zookeeper 保证 order。在后文里有写这个 read order 指的不只是执行顺序 FIFO,还要有不能回头读的意思。
sync 做的就是把 read 命令先挂起,然后 replicas 向 leader 拉取新的数据,注意这个新数据并不指的完全新,只是到 read 需要的那个 point 就行了。
# Examples of primitives
# Configuration Management
Zookeeper 需要使用到动态的 configuration,但是它实现这个的方式知识将 config 存在在一个 znode 中, 。processes 启动后会读取 获得配置,并且设置 watch flag。当 configuration 修改之后,process 可以获得 notification 并且读取最新的 configuration。
# Rendezvous
有时候,client 需要启动一个 master process 和一些 worker process,但是这个 starting processes 是被调度器完成的,因此 client 并没有办法预先知道 master 暴露的端口和地址。Zookeeper 使用一个 Rendezvous znode, 来解决这一问题。master 启动之后,会把自己提供服务的端口和地址写到 中。worker 启动之后就读取这个 znode,并且设置 watch flag。
# Group Membership
这个很好理解,说白了就是为一个 group 设置一个 znode,。当这个 group 的 process 启动时,就会在这个 下创建子 znode。这些 znode 是 ephemeral node,如果 client fail 或者 session 关闭后,zookeeper 会自动回收。因此,要得到 group 信息只需要看 的子节点就行了。同时还可以设置一个 watch flag,当 group information change 时候接收通知。
# 锁
# 简单锁
最简单的实现锁的方式就是创建一个 ephemeral znode。如果 client 创建该文件成功就意味着获得锁,如果删除该文件就意味着释放锁。但是这就一个问题,如果有很多用户同时在申请锁,那就无法满足按申请顺序获得锁。(Herd Effect)
# Simple Locks without Herd Effect
它的实现方式很巧妙:

- 申请锁时,先创建
znode l下的子 znode。并且设置 Sequential 和 ephemeral。 - 获取
znode l的所有 children。 - 如果 n 是 C 中最低的 znode,那么获得锁。
- 查看 n 之前的那个 znode p。
- 如果 p 存在那么 wait,否则跳转到 2。
这里需要注意,最后跳转是跳转到步骤 2,因为 znode p 对应的那个 client 如果关闭了 session,那么系统会自动回收这个 znode p。也就是说 znode p 不存在并不意味这 p 刚刚释放了锁。
# Read/Write Locks

看图说话罢了。
# ZooKeeper Implementation
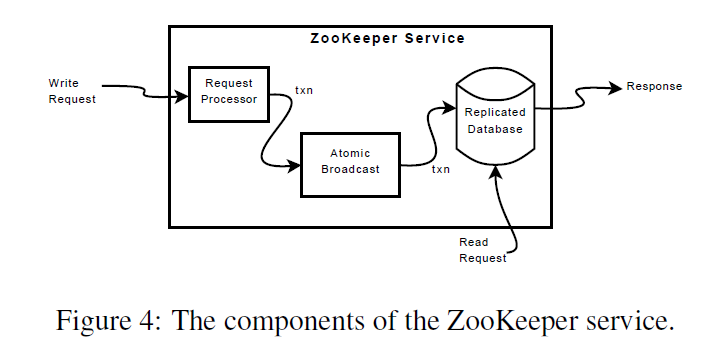
这块内容没怎么看懂。。。但是这个 听课的时候大致听懂了,这个 就是为了防止出现 read back 操作。
每一个 read 操作都在一个 上进行, 只能随着读操作增大,当切换 replicas 的时候,read 操作也要在相同的 上进行。
# 听课

zookeeper 并没有实现线性一致性,它允许读到 stale data。

zookeeper 实现 mini-transaction:
data, v = GETDATA(p, watch)
SETDATA(p, data+1, v)
zookeeper 通过 getdata 会返回当前 data 的 version,setdata 如果 replicas 中 dataversion 一致才能 setdata。
这就实现了一个 mini-transaction