# 开新坑了!
令人感叹,自己虽然开了很多个坑,但是能够完成的却很少,这次的 MIT6.824 是我确定学的一门课程,要想入门分布式绕不开的一门课,没办法,老老实实学一次,把所有的 lab 做完,这就是我的目标!
# 论文阅读
因为这门课必须要看论文,所以就很痛苦。。。
# 问题
原有的计算是很简单的,但是因为数据很大需要做成分布式系统,所以如何 并行化计算 、 分发数据 和 处理故障 等问题使得原本简单的计算变得晦涩难懂,需要大量复杂的代码来处理这些问题。
# MapReduce 函数
map(String key, String value): | |
// key: document name | |
// value: document contents | |
for each word w in value: | |
EmitIntermediate(w, "1"); | |
reduce(String key, Iterator values): | |
// key: a word | |
// values: a list of counts | |
int result = 0; | |
for each v in values: | |
result += ParseInt(v); | |
Emit(AsString(result)); |
map 用于发射中间键值对,而 reduce 函数则负责对中间键值对中相同的 key 进行 aggregate 处理。
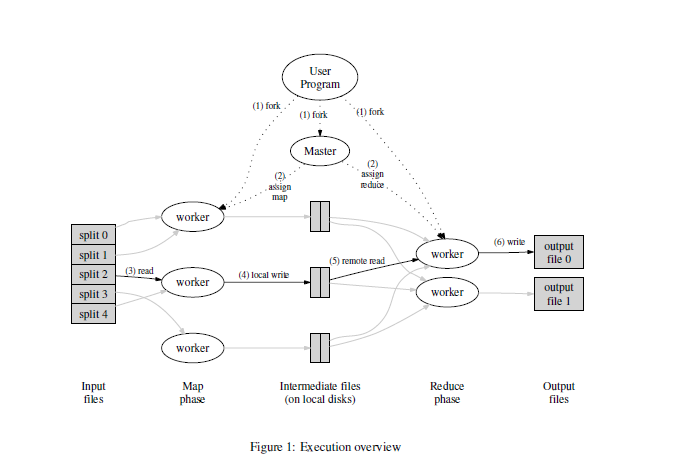
# 执行概述
首先明确 map 机和 reduce 机组成了一个分布式系统,所以这里有一个 master 机用于 assign 任务。
- 将 raw data 切分为 M 个 splits。每一个 split 大小可以由用户进行指定。
- master 机将 map 任务和 reduce 任务分别自拍给不同的 workers。
- map 机读取 input split,通过
Map函数将 k/v 对进行输出。这些中间键值对缓存在 map 机的内存中。 - 这些缓存的键值对会定期存本地磁盘,同时会被分区函数分为 R 个 regions。可以用 hash (key) mod R。local disk 的位置会被发送给 master 即,master 机来告诉 reduce 机存储位置。
- reduce 机被 master 机告知存储位置后,通过 rpc 远程调用来读取有 map 机制造的缓存 kv 中间对。当 reduce 机读取完了所有的数据后,会通过 sort 操作来将相同 key 进行 group。因为中间数据可以过大,以至于难以读入到内存中,因此 sort 操作是必须的。
- reduce 即使用
Reduce函数来对这些数据进行处理,并将数据输出到最终的分区。 - 当 mapreduce 操作执行完毕后,master 机负责唤醒用户程序,并把 MapReduce 调用输出返回给用户程序。
# 使用例子
计算 URL 的频率,这个就和 wordcount 函数相同。
ReverseWeb-Link Graph: map 函数输出 <target, source>,target 是对应的 url,而 source 就是 target url 出现的网页 URL,而 reduce 负责将 source 进行 concat,输出 < target, list (source)>
Inverted Index: 和上面的例子类似。
# 分布式系统的特性
# 错误容忍
Availability:即使一些机器发生了故障,系统依旧可以提供无误的服务,注意,如果很多机器都宕机,available system 仍然会停止运行,但得到修复后,系统可以继续正确运行。
Recoverability:系统发生故障后,经过修复仍然可以正确运行,因此 Availability 就包含了系统需要 Recoverability。

# LAB1
# Job
实现分布式 MapReduce,包含两个程序,master 和 worker。worker 和 master 之间通信通过 RPC,每个 worker process 将会向 master 询问任务,读取任务输入,执行任务,并将任务结果输出到一个或多个文件中。如果 worker 不不能在 10s 的时间内完成任务,master 需要将任务分配给另一个 worker。
执行过程:
生成插件
go build -buildmode=plugin ../mrapps/wc.go |
在 main 目录下执行:
go run mrmaster.go pg-*.txt |
这个就是 master 函数
执行 worker
go run mrworker.go wc.so |
# 需要遵守的规则
- map 函数传递的中间 key 需要分配到 nReduce 个 bucket 中,而
NReduce这个参数会被main/mrmaster.go传递给MakeMaster() - 结果需要保持为
mr-out-X这种格式,其中X是reduce的编号。 mr-out-x文件中每一行记录了 reduce 的输出,并且格式为%v %v- 只能改动这三个文件
mr/worker.go,mr/master.go,mr/rpc.go。 - worker 需要把 map 的中间结果保存到当前目录中。
- mr/master.go 中需要实现
Done()方法,如果返回true表示 MapReduce 任务执行完成,mrmaster.go才会退出。 - worker 还需要实现
call方法,如果 worker 不能和 master 进行沟通,那么 worker 就会终止。(还可以实现一个 pseudo-task,这个任务就是”please exit".
# 提示
mr/worker.go通过 RPC 向 master 进行 task,master 发送一个还没进过 map 的文件名,然后 worker 就开始读取这个文件并调用 Map 函数。- Map 和 Reduce 函数不用自己写,已经在 plugin 保重实现了。
- 每次都要先 ``go build -buildmode=plugin ../mrapps/wc.go`
mr-X-Y的方式给中间文件命名,X 值 Map task, Y 指 Reduce task。- kv 键值对可以使用 json 文件格式进行存储。
- The map part of your worker can use the
ihash(key)function (inworker.go) to pick the reduce task for a given key。也就是说ihash方式在 map 阶段就知道这个 key 该由哪个 reduce 进行处理。 mrsequential.go的代码可以借鉴。注意 sort。- master 作为 RPC 服务器,它是并发的,所以到注意加锁。
go build -race可以用作检查并发。- 所有的 map 执行完毕之后 reduce 才会执行,所以 reduce worker 需要等待。
- 对于执行超时的 worker,master 需要重新分配任务。
mrapps/crash.go用于检测崩溃回复。- map 函数先用一个临时文件写中间数据,当所有的数据写完之后,在将文件名自动重命名。
# 遇到的问题
- taskstate 0 空闲 1 处理中 2 处理完毕
- 坑点:只有当前 worker 执行完了一个 maptask 或者 reduce task 才能再执行 map 或者 reduce task。不能在一个 worker 机上同时并发执行多个 Map 或 reduce 函数。
- 写中间文件需要使用 os.O_TRUNC,不然执行 sh 脚本会出错。
- 最后的测试点只能用 Sock 方式进行 rpc,不能用 tcp 方式。
# Repo
代码放在了 github 上:
MapReduce
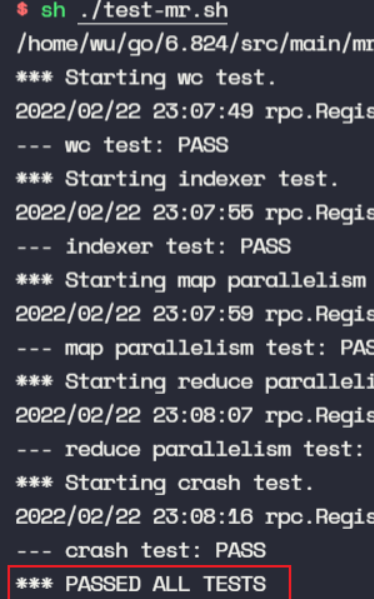
完成了所有测试点: