首先我是读了论文之后再写这个 lab 的,但 raft 论文的内容太多了,只能慢慢一点点看。现在还是先把 lab 完成。
强烈安利:https://mp.weixin.qq.com/s/lUbVBVzvNVxhgbcHQBbkkQ
先上图
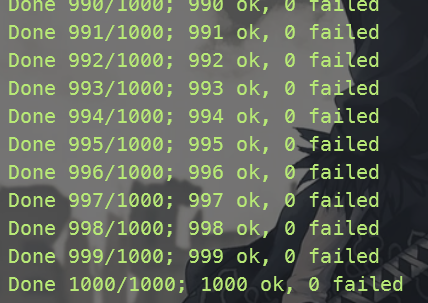
4 个小题全部通关,并且并行测试 1000 次无出错。
# Part 2A
任务要求:实现选举算法和心跳包。如果旧的 leader 没有问题就让旧的 leader 继续执行,如果旧的 leader 有问题那么就选举新的 leader。
这意味着我们不用设置 normal term,只要考虑 leader fail 这种情况。
任务提示:
- 完成
raft.go - 完成
RequestVoteRPC - 实现
AppendEntriesRPC - 注意不要发生同时进行选举的情况。
- 要求 leader 发生心跳包每秒不超过 10 次。
- 要求旧的 leader fail 5 秒内完成选举。
- 因为 tester 旅程每秒只能发送 10 次心跳,所以 election timeout 必须要大于 paper 里描述的 150-300。
# Part2B
# 3.3 更新
我真的想干死他妈了,折腾了好几天终于无伤打过 LAB2B,运行 100 次也没有出错,这里面的坑点真的很多。

首先需要明确 committed 是如何被确认的:
对于 leader 来说:nextIndex -> matchIndex -> commitIndex -> applyIndex
If there exists an N such that N > commitIndex, a majority of matchIndex[i] ≥ N, and log[N].term == currentTerm: set commitIndex = N
刚开始我也搞不懂这个 matchIndex 是什么东西,leader 是通过 check majority matchIndex 并且如果该 log entry 属于当前 term 就确认 committed。
对于 follower: **preLogIndex -(匹配成功)> len (logs) -compart with leadercommitted> commitIndex -> applyIndex **
commitIndex = min(len(logs) , leaderCommitted
对于 follower 来说可以是 leader 告知 committed,也可以是通过 append log 后自己确认,总之这个过程逻辑自洽。
但是这个有一个很严重的坑点,会导致时不时出现 index out of range 这个错误。这个错误其实有在 raft guide 上写明,但是我当时并没有看懂,导致执行 100 次总有几次报这个 out of range 错误。。。。
出现这个问题的原因就是 follower 应用了 stale AppendEntries PRC,然后给 leader 发送了 reply success = true。因为 leader 会重复发送 AppendEntries PRC,如果某个 AppendEntries PRC 返回 true 后,leader 就会执行:nextIndex[server] += len(args.entries),这就导致有时候 leader 会将相同的 AppendEntries PRC 应用两次后,nextIndex [server] += len (args.entries) 也执行两次。最后导致 nextIndex [server] 要超过了 log 的长度。
解决方法:
last := rf.logs[args.PrevLogIndex+1 : len(rf.logs)] | |
// 难点在于如何判断旧的 rpc | |
if len(last) == len(args.Entries) && len(last) != 0{ // 判断要 append 的 log entries 是不是已经 append 上了 | |
flag := true | |
for i := 0; i < len(last); i++ { | |
if last[i].TermNumber != args.Entries[i].TermNumber { | |
flag = false | |
break | |
} | |
} | |
if flag { | |
reply.XTerm = -2 // 表示这个是过时的 rpc | |
return | |
} | |
} |
还有一个很严重的坑点,就是选举超时重置,它会导致 rejoin of partitioned leader ... 这个测试时不时失败,这是因为选举不当,导致 cluster 没有及时选举出 leader。
这里需要注意,什么时候才会重置 election timeout:
- 当 follower 升级为 candidate 时会重置。
- 当 follower 投出自己的一票时会重置。
- 当 follower 接受到 leader 的 appendEntries PRC 时会重置。
第一种情况很简单,就是因为超时才会升级为 candidate,所以成为 candidate 后必须重置。
第二情况有些复杂,如果一个 leader 或者 candidate 接受到一个 vote request,其中 rf.currentTerm < args.Term。这说明该 leader 或者 candidate 已经 out of date,必须强制转换为 follower,注意,强制转换为 follower 并不代表它可以重置它自身的 election timeout。只有满足严格选举要求,把自己的票投出去后才可以重置。follower 在每一个 Term 有且只有一张选票!但 server 进行 term 提升后就可以分配一张新选票。
第三种情况其实和第二种情况类似,appendEntries PRC 只能由 leader 发出,一旦当前 server 确认其自身的 currentTerm <= args.Term 就会把选举时间重置。
只要注意这两个问题:旧 AppendEntries 和 election timeout,就可以轻松 pass all test 了!
# Part 2C
这个 lab 要求我们实现 persistence。
# 3.3 更新
无伤通关,就很 nice!

执行超过 100 次,仍然这么坚挺!太佩服我自己了,嘿嘿😄
这个基本思路很简单,就是实现 persist ,然后把 persist() 插入到 persist state 变换的地方,通过 figure 2 不难知道:

只要这三个变量改变的时候,我们就插入 persist 。
但是这里也有一个坑点,这就 appendEntries RPC 会因为网络出错,下面我来描述一下出错情境:
首先明确,因为我们会不断重复发 AppendEntries RPC,这就导致 follower 需要检查,这个 AppendEntries RPC 是否已经过时,如果过时就返回 false,如果没过时就返回 true
# TestFigure8Unreliable2C 报错,返回 true 的 AppendEntriesRPC 丢失问题
原因在于,leader 首先发送了一份 entries,follower 通过 AppendEntries 收到了这份 Entries。follower 检查到这个 AppendEntries 中携带的 Entries 没有被 Append 到自己的 logs 中,于是它 append,并返回 true。但是这个本该返回 true 的 AppendEntries RPC 因为网络没有返回(永久丢失,或者返回很慢,leader 超时不再接受),leader 于是又重新发送了一份相同的 Entries。follower 检查到这个 AppendEntries 中携带的 Entries 之前已经 Append 过了,于是它返回给 leader false。leader 收到 false 后于是重复发送,于是整个系统陷入了 living lock 。
解决办法:当 follower 检测到 stale AppendEntriesRPC 时,它告诉 leader,这个 RPC 过时了,并且同时返回 follower 自己的 len(logs) 也就是 XIndex 。leader 检查到过时的 RPC,它通过检查 reply.XIndex == len(args.Entris) + rf.nextIndex[server] ,如果满足说明它没有接受到那个返回 true 的 AppendEntries,于是它将 rf.nextIndex[server] = reply.Xindex 。至此,我们就能够解决返回 true 的 AppendEntriesRPC 丢失问题。
# unreliable churn out of range 问题
原因在于,网络太混乱了。在上面我们提到,返回 true 的 AppendEntriesRPC 会因为网络丢失,然后 leader 一直陷入活锁。我们的解决办法是告诉 leader,这个 AppendEntries 过时了,leader 来检查需不需要修改 rf.nextIndex 。
但是!!!
你有没有想过,因为网络很乱,如果 stale appendEntriesRPC 要比那个返回 true 的 AppendEntriesRPC 先返回呢?leader 对于 stale AppendEntriesRPC,它会认为自己之前的那个返回 True 的 AppendEntriesRPC 丢失了。于是 leader 修改了自己的 nextIndex。但是那个返回 true 的 AppendEntries 因为网络还可以,最后还是成功返回了。leader 于是又修改了自己的 nextIndex 。这就导致了 out of range 的出现,并且这个问题是偶发性的,因为这属于网络中的极端情况。
我们的解决办法也很简单,如果 leader 要修改自己的 nextIndex,必须满足:
reply.XIndex == len(args.Entries) + rf.nextIndex[server]
# TestFigure8Unreliable2C 稀有 out of range
因为我的 log 日志的 index 是从 1 开始的,于是在初始化时候,我会默认将 index = 0 设置为 0, applyindex =0 , commitIndex= 0。
但是在设置 nextIndex,因为日志不匹配,我就需要遍历找到最优的 Index,但是这里我的遍历条件是:
for i = len(rf.logs) - 1; i >= 0; i--
这就会导致在很罕见的情况下,i 会被归为 0,而我们用 0 给 nextIndex 赋值,就导致 preLogIndex 变成了 - 1。这就会出现 out of range。但这个情况很少见,100 次里能出现 1 次?
改成: for i = len(rf.logs) - 1; i >= 1; i-- 就行了。
都是细节!真的太细了。。。。
# Part2D
这个 lab 要求我们完成 log compaction。
需要实现 Snapshot(index int, snapshot []byte) ,tester 来定期调用。
# 无伤通关!!!!!(3.4 更新)
终于无伤通关了 lab2 了,真的服了我自己了。
批量测试还在跑,但是问题不大,嘿嘿。
2D 其实很简单,就是需要将原来的索引进行替换,我的选择是写两个转换函数:
func (rf *Raft) Convert(index int) int { | |
return index - rf.lastIncludedIndex | |
} | |
func (rf *Raft) Reconvert(index int) int { | |
return index + rf.lastIncludedIndex | |
} |
在刚开始我的想法是,因为每一次做 snap 都会切断 logs,于是需要考虑处理空 log 日志的情况,但是其实没有必要,如果考虑空 log 会导致整个代码逻辑变得非常复杂。
解决方法:每一次做 snapshot 得到新的 log 时候,我们在 logs 前面插入一个空 log entry,并且它的 term 等于 lastIncludeTerm 。于是我们之前写的代码就只要一点点改变。
第二个坑点就是,选择什么时候调用 Installsnapshot。我最开始想的是在 sendAppendEntries 在这个函数的返回逻辑部分进行处理,但是由于 RPC 是建立在 UDP 上的,整个网络异常混乱,导致可能多个 Installsnapshot 调用之间顺序很乱,不利于我们的思考。
解决办法:把调用 Installsnapshot 放到 heartbeat 函数里,让每一次 heartbeat 考虑要不要调用 installsnapshot。
# Installsnapshot RPC

按照要求实现这个 RPC 就行了,需要注意因为整个网络不可信,我们需要验证这个 InstallSnapshot 是否已经过时。
# 遗留的问题
这是我做这个 lab 发现的一个很奇妙的现象,但我完成了 2D 的时候,回过头我检查之前的 ABC 测试,发现 B 测试中的 *😗 RPC byte count 测试出现 RPC byte count failed。
这个问题是因为,整个网络是 UDP 的,会出现这么一种情况:RPC 包发出去后,因为 UDP 广播,被自己立即接受了,并返回。这样就使得整个网络变得异常臃肿。
这个 Bug 出现的原因是因为,我在代码中增加了这样一个逻辑,一旦检查到自己发出的 RPC 包被自己接收后就 return。
但是我至今也没搞懂,为什么不行!
这个问题,未来的我,你可以解决的对吧?😏
# Raft Basic
将 servers 分为三种状态:leader、follower 和 candidate。
follower 是消极的,他们只能响应 leader 或者 candidate 的请求。candidate 是选举时产生的。
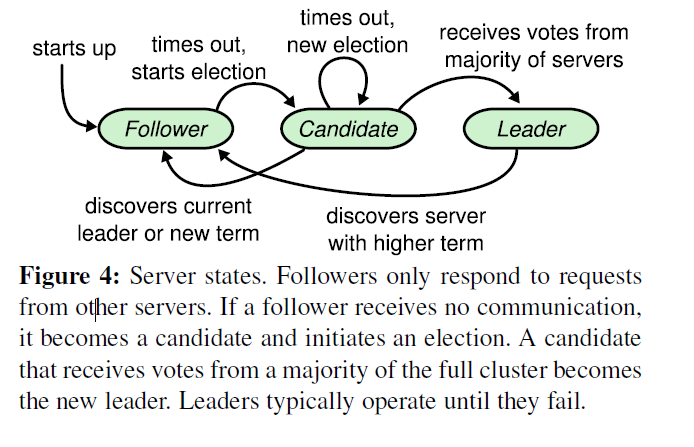
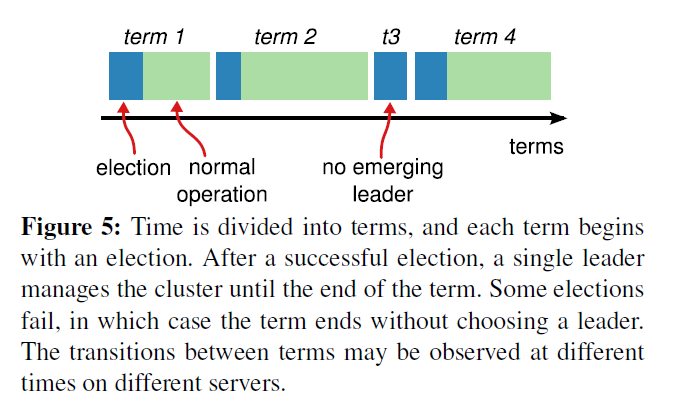
就像图中描述的,term 分为两个阶段 election 和 normal。每个 term 都有对于的 current term number。如果 candidate 或者 leader 发现他的 term 过时了,那么他们会自动变为 follows。
RequestVote RPCs 在选举时由 candidate 进行初始化,并且 AppendEntries RPCs 被 leader 初始化用于复制 log entries 和提供 heartbeat(就是空的 AppendEntries)。
记住 raft 中的节点其实就是状态机!

这里我有一个想法,因为是 state machine,由于 raft 层记录了 lastApply,而且 state machine 只能 apply committed entries。所有的机子都会 apply 相同的 committed entries。因此这里可能会出现重复响应情况,比如 client 发送请求给 leader,leader committed 请求后返回给 client 响应之后马上挂掉了,raft 通过选举产生了新的 leader,那么新的 leader 可能会让 state machine 重复 apply,也就是重复发送响应。
但是这没有问题!重复是 tcp 层应该解决的问题。
LastApply 永远应该小于或等于 committed index!
# Leader 选举
server 开启,初始状态为 follower,并且如果他收到 leader 或者 candidate 的有效 RPCs,那么就会一直维持 follower。如果 follower 在 election timeout 内没有收到任何 RPCs,那么他就会增加 current term 并且成为 candidate 开启选举。
# follower

# candidate
通过 RequestVote RPC 同时向集群中所有的 server 要求投票。
# RequestVote RPC 的结构:

# candidate 需要做的:

这里其实还少些了一个很重要的条件:
Current terms are exchanged whenever servers communicate; if one server’s current term is smaller than the other’s, then it updates its current term to the larger value. If a candidate or leader discovers that its term is out of date, it immediately reverts to follower state. If a server receives a request with a stale term number, it rejects the request.
也就说如果 leader 或者 candidate 发现有人的 current term number 比它的还要大,那么就自动变成 follower,这个特性很重要!
# 关于 randomized election timeouts
论文中提到:
raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly.
这个一直困恼我,整个随机 election timeouts 是如何解决 split votes。因为有一段话:
This spreads out the servers so that in most cases only a single server will time out; it wins the election and sends heartbeats before any other servers time out.
这段话的意思是说先 timeout 的 server 会获得选举胜利。这里就有一个疑问为什么先 timeout 的 server 一定会获得选举胜利。其实要搞懂还得看 follower。follower 做了一件事:
If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader.
如果 follower 在 election timeout 没有收到 leader 或 candidate 的 rpc,那么它会开启选举,注意这里的超时时间是 election timeout 。也就是说过 leader 挂了的话,那么 election timeout 最小的那个机子就会先意识到,于是他成为 candidate 并且向其他 server 发送 RequestVote RPC。而 raft 的投票机制就是先来先到规则,先发起投票的那个 server 很有可能可以赢得选举。
candidate 初始化也做了一件事:
Each candidate restarts its randomized election timeout at the start of an
election, and it waits for that timeout to elapse before starting the next election
candidate 初始化后也会重新随机初始化这个 election timeout 。如果在这个阶段发生了 split vote 情况,那么 election timeout 最小的 candidate 就会率先超时,并且开启新的投票,于是其他 candidate 看到新的 RequestVote 中的 current term 大于自身的 term number,于是这些 candidate 就会自动变成 followers 并给新的 candidate 投票。于是 splitvote 问题就可以很好地解决了!
# State
# 所有的 server 都有的状态
committedIndex :这就是 logs 中 committed highest log entry index,这个初始化为 0。
log[] :log 初始化中会把 index 为 0 初始化,也就是后续添加 entry 的 index 都是从 1 开始。
lastApplied :index of highes log entry applied to state machine。通过 heartbeat 发送了 entry 之后受到了 confirm,确定是 committed 之后就可以执行了。这个 lab 可能不会涉及。
commitIndex :通过 heartbeat 得到回复,leader 就可以确认 committed 了。
# leader 维护的状态
matchIndex[] :对于每个 server,需要复制的最高 log entry index,初始化为 0。我还没搞懂这个最高需要被复制为啥要初始化为 0。
nextIndex[] : leader 会保存下一个为 server 发送了 log entry 的 index。这里的 index 我直接设定为 log 的索引。(初始化为 len(logs) )
# 关于 5.4 Safety
有个大前提:leader 可以无限 append log,但是它不能通过选举然后增大自己的 term。
# 严格选举
Raft 保证新选举出来的 leader 必须拥有之前 term 所有的 committed entries,也就是说 log entries 只能通过 leader 流向 follower 而不能从 follower 流向 leader。
这里 candidate 赢得选举的条件有所不同。
candidate 在请求投票时,会发送自己的 last log entry 和 follower 的 last log entry 进行对比。如果 candidate last log 的 term 要大,获得 term 相同时 candidate log entry 的 index 要大,则认为 candidate 是优先的,这时候才能进行投票。
# committed 规则
论文的 figure 8 给出了这样一个情况:
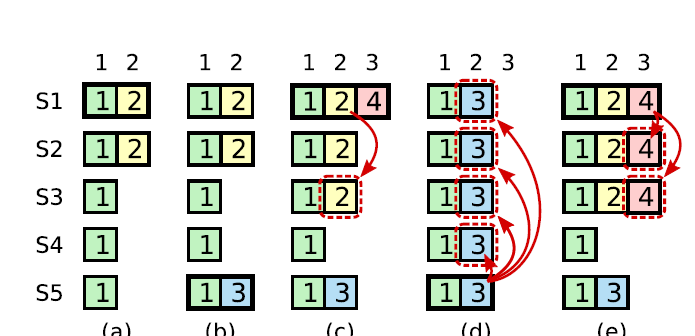
在 c 情况下, s1 作为 leader 将 index 2 复制给了 s2、s3。然后问题来了,这样 index 2 就是一个 committed entry 了,但是如果 s1 这时候挂掉,s5 参与到选举,由于 s5 在 term3 时候赢得了选举,所以他有 term3 的 log entry,那么 s5 在 d 情况可以赢得 term5 选举,并把 index 2 复制给了其他 server。可以看到此时的 index 2 的 term 变成了 3。之前的 committed 被覆盖了!
于是 raft 规定,只有当前 term 的 log entries 才能通过计算 replicas 数的方式进行 committed 。
这里又会有新的问题出现了!如果一个 command 对应了 log entries 是之前的 term,那么及时当前 leader 收到了 majority 的 confirm,那么 leader 也不能 apply 这个 log entry。一直到当前的 term 下来了 new command。那么这个旧 term 下的 log entry 才会得到 confirm。
# Safety argument
针对 figure 9 的情况

我对于这张图的理解
如果 s5 可以获得大部分选票的话,那么至少会出现 s3 这种既收到了之前 leader 的 log entry。请注意,论文描述严格选举有一个前提,那就是:赢得选举的 server 必须要在 majority 中保证 up-to-date log entry。这意味着 leader 如果自己任期内的 committed entry 一直是 up-to-date。也就是说 s5 不可能通过选举!
有一说一,还是有的抽象。。。。
# Timing and availability
需要保证
broadcastTime≪electionTimeout≪MTBF
broadcastTime 就是平行发送 RPCs 的平均发送时间 + 接受响应时间。
electionTimeout :这个就是之前提到了选举超时。
MTBF :the average time between failures for a single server
MTBFs are several months or more,所以这个不等式很容易满足
# Log compaction
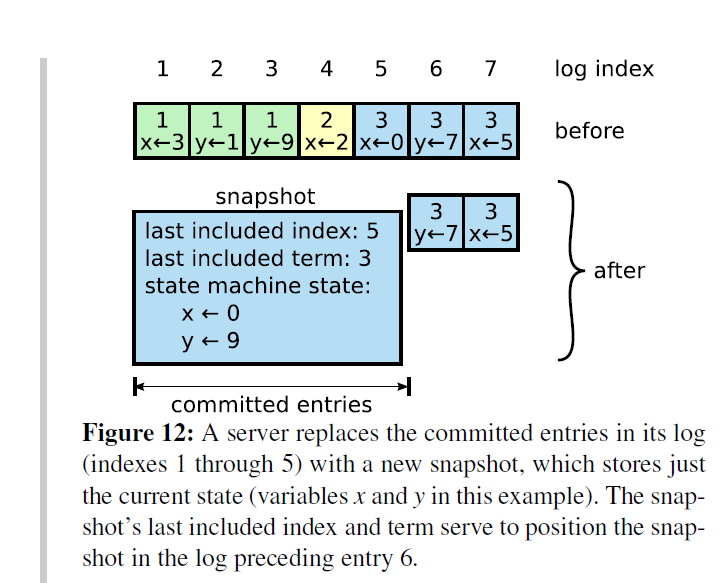
raft 的 snap 机制用于压缩日志,其实它也很简单。
last included index 就是 the last entry the state machine had applied,就是 last apply index,注意,只有 committed 的 entry 才会被 apply,而 raft 可以确保所有 committed entry 都会在 state machine 得到 apply。
** 并且这个 snapshot 还包含 state machine state!** 这是创建 snap 的最大开销。
所以之前已经 apply 的 log entry 实际上已经没啥太大帮助了,我们只需要保存 last 用于 AppendEntries consistency check。
对于特殊情况,比如 leader 现在需要废弃 log entries,但是这些 log entries 中还有一些没有发送给某个 follower,比如 follower server 执行很慢,这个 server 刚刚加入网络。。。
于是这是 leader 会调用 InstallSnapShot RPC:

leader 通过发送 chunk 方式,把 snapshot 发送给 follower。
如果 follower 的 last log entry 比接收到的 snapshot 里的 last index 还要 stale,那么 follower 就把全部 log entrie 给扔了。如果 follower pre index 和 snap 里的 last index 重合,那么就只丢弃之前的。
snapshot 的创建规则:
- 固定 log size 触发创建 snapshot。
- copy-on-write 技术用于创建。
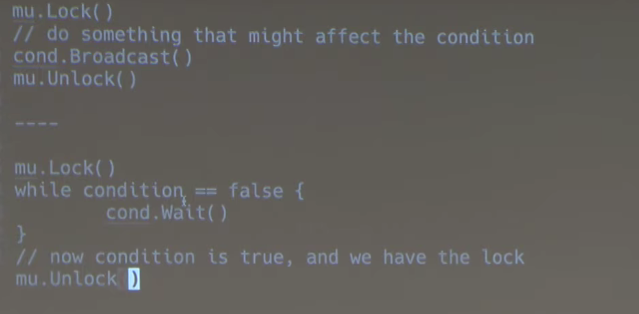
# 听讲
使用 condition




这张图很好地解答了我的疑惑,raft 中的 server 只能是 leader 来对外提供服务,从 client 发送请求到 leader 响应过程分为:
- client 向 server 发送请求,发送给 follower 的请求会被 follower 转发给 leader。
- leader 把 client command 写在 log 中,并通过 Append Entites RPC 发送给其他 followers。
- followers 返回确认消息,如果集群中 majority 都响应了,也就是说 leader 知道了 cluster 中大部分节点就收到了这些 log entity,那么对应的 entity 就是
committed。 - leader 确认 entity 是 committed 之后,就会开始执行 entity 对应的 command,并把执行这个 command 再次发送给 followers。
- followers 收到确认执行 request 之后开始执行。
我之前想到的 split partition 问题就可以很好解决了,如果集群分裂为两个 partition,然后各自都有 leader,那么对于 min partition 来说,leader 收不到 majority 的确认,因此 leader 没法执行指令。

raft 使用 fast backup 方法。
# 线性一致性
# 什么是线性一致性?
Raft 里提到的线性一致性:
Linearizable semantics (Linearizability)(each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response)
在一个线性一致性的系统里面,任何操作都可能在调用或者返回之间原子和瞬间执行
线性一致性,Linearizability,也称为原子一致性(atomic consistency),强一致性(strong consistency)等
也就是通常所说的 CAP 理论中的 C
实现线性一致性需要满足三点:
- 瞬间完成(原子性)
- 发生在 Inv 和 Resp 两个事件之间
- 反映出 “最新” 的值
1 和 2 很好理解,但 “最新” 怎么理解呢?其实很简单就看写操作: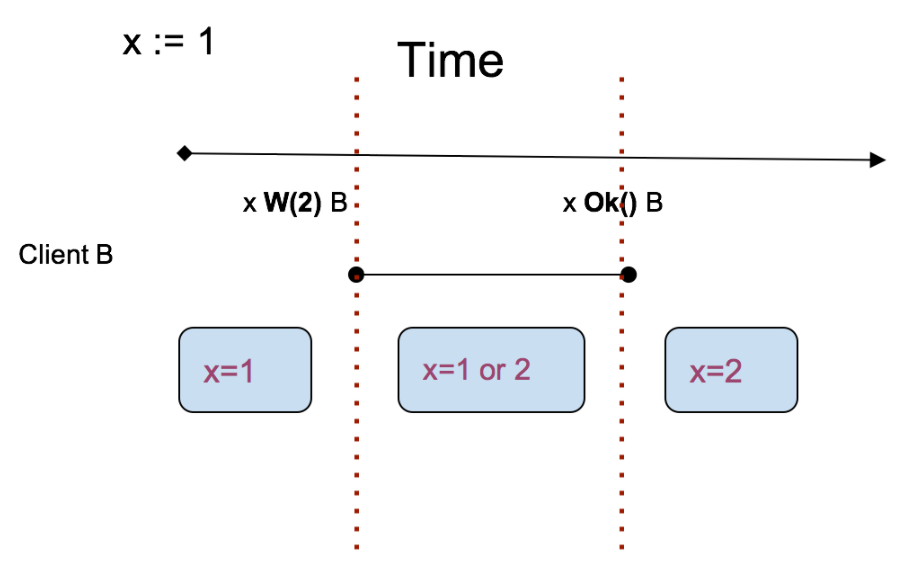
在图中,x 的值被写操作划分为 3 个区域,每个区域内对应最新的值,也就是说 “最新” 并不代表确定!
# 教授讲的线性一致性
我觉得教授讲的更加言简意赅:
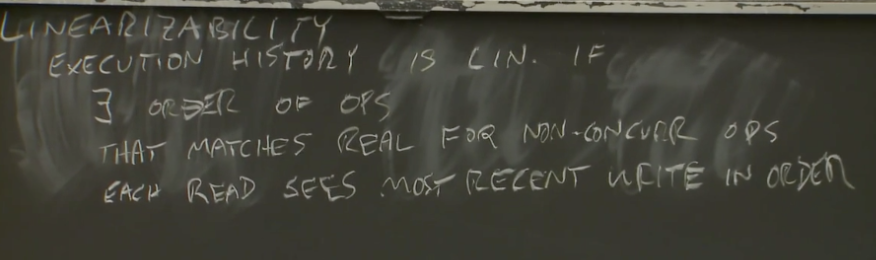
如果执行历史是线性的,那么存在操作序列,满足执行顺序和真实时间相匹配,每个读操作一定看到了最新写操作结果。
我们以下面这张图为例子:
执行顺序和真实时间相匹配:对于非并发也就是时间上不重合的请求,比如 w1 和 w2。这两个请求在时间上不重合所以一定是 w2 发生在 w1 之前。但是对于并发也就是时间上有重合的请求,则需要 each operation appears to execute instantaneously 。
每个读操作一定看到了最新写操作结果:这句话的意思就是 R 一定发生在 W 之后,比如读 R1 一定发生在 W1 之后,假如没有最新的 W 操作,那么之后所有读操作一定都是返回 1 的。

# 遇到的问题
# 2.27 日更新:
成功完成了 Lab2A,但是还遗留了一个问题,那就是为什么限制选举执行时间才能通过 test,按道理只要选举超时之后,之前选举的结果就会被废弃的。。。
Test (2A): initial election ...
labgob warning: Decoding into a non-default variable/field Term may not work
... Passed -- 3.0 3 56 6872 0
Test (2A): election after network failure ...
... Passed -- 9.2 3 238 17813 0
Test (2A): multiple elections ...
... Passed -- 6.5 7 642 55493 0
PASS
ok 6.824/raft 18.733s
# 3.1 号更新
raft 在 leader 当选之后会立即在 leader 的 log 中生成一条 no-hup 日志并通过 heartbeat 传递给其他 server。但是在 MIT6.824 实验中没办法实现 no-hup。
# 3.4 更新
愉快通关!