# GFS(Google File System)
In this paper, we present file system interface extensions designed to support distributed applications, discuss many aspects of our design, and report measurements from both micro-benchmarks and real world use.
这篇文章介绍旨在支持分布式应用程序的文件系统接口扩展,讨论了我们设计的许多方面,并报告了从微基准测试和真实世界使用两方面的测量结果。
# Keywords
Fault tolerance, scalability, data storage, clustered storage
# Introduction
constant monitoring, error detection, fault tolerance, and automatic recovery must be integral to the system.
作者认为持续监控,错误检测,故障容忍,自动恢复是系统的关键所在。
# 设计理念
- 系统由许多便宜的机器组成,所以经常会有 fail 情况,监控、检测、故障恢复是日常。
- 系统会存储很多 GB 级别的大文件。
- 读负载主要分为两种:大流式读和小的随机读。
- 写负载通常是 append data。也就是说文件是被 append 而不是修改。因此一个文件一旦写完之后就很少被修改。
- 系统实现了多客户端并发 append 同一个文件
- 高稳定带宽比低延迟更重要。
# 架构
一个 master 机(以及多个 master 机的 remote 副本),多个 chunkservers,以及多个 clients。
每一个 chunk 有 64M,并且被一个 64bit 的 chunk handle 给唯一标识。chunkhandle 是 chunk 创建时由 master 机分配的,并且如果 client 要访问 chunk 并且持有 chunk handle。
# 读操作
- client 将 filename 和 byte offset 转成 chunk index。
- client 向 master 发送 request,包含 chunk index 和 filename
- master 返回 chunk handle 和副本的 location。
- client 使用 filename 和 chunk index 作为 key,将 master 返回的数据作为 value,缓存起来。这样 client 在一段时间内就可以不用再和 master 沟通了。
- client 访问距离它最近的 replicas。
# MetaData
三种主要的 MetaData:the file and chunk namespaces, the mapping from files to chunks, and the locations of each chunk’s replicas。
主要 MetaData 都是存放在 Master 机的内存中,但是 namespace 和 mapping 是会写到 local disk 的 log 中,并且在 remote 机中存放备份。但是 location 不会有持续存储。
因为集群经常会有机器加入、宕机、重启等情况,所以持续化存储 location 不是一个好的选择,最好还是周期性询问 chunkservers。

# consistent 和 defined
如果所有 client 看到相同的数据,就被认为是 consistent。
如果文件数据改动后,file region 还是 consistent 的,并且所有 client 都会看到 mutation writes 的全部内容,那么就说明 region 是_defined_。

对于 GFS 来说,write 和 append 虽然都是 mutation 但是他们还是有不同的。
# Write 和 Append
说实话我读第一遍论文时候搞不懂为什么 write 操作是 undefined 但 consistent 而 Record Append 操作是 defined 但 inconsistent。其实这个不同点就是 GFS 设计的巧妙之处,write chunk 操作需要制定 offset,而 Append 操作则不用。
教授关于 Append 操作的这个例子讲的很好:

对于 append 操作,如果第一次 Append 操作失败之后,那么会重新发起 append 请求,也就是 primary 再写一遍然后让其他副本也写一遍,那么问题就来了,之前的 Append 操作中,有的 replicas 成功写入了 data,有的没有。失败的操作不会要求这些 replicas 删除之前 append 失败操作写的数据,而是重新再尾部进行 Append,并且要求同一个 Records 在所有的 replicas 中具有相同的 offset。那么很显然上述的三个 replicas 中数据是不一致的,但我们可以看到每一个 append 操作写的数据,数据不会被覆盖,那么他就是一个 defined 操作。
对于 write 操作,因为所有 client 机并发写相同的 offset,那么及时失败后,有的 replicas 写了,有的没有,那么在下一次重新发起 Write 操作中,会写覆盖掉之前写的数据。因此 write 操作是一致的,并且因为写覆盖,我们没法知道到底是什么序列写的,所有是 undefined。

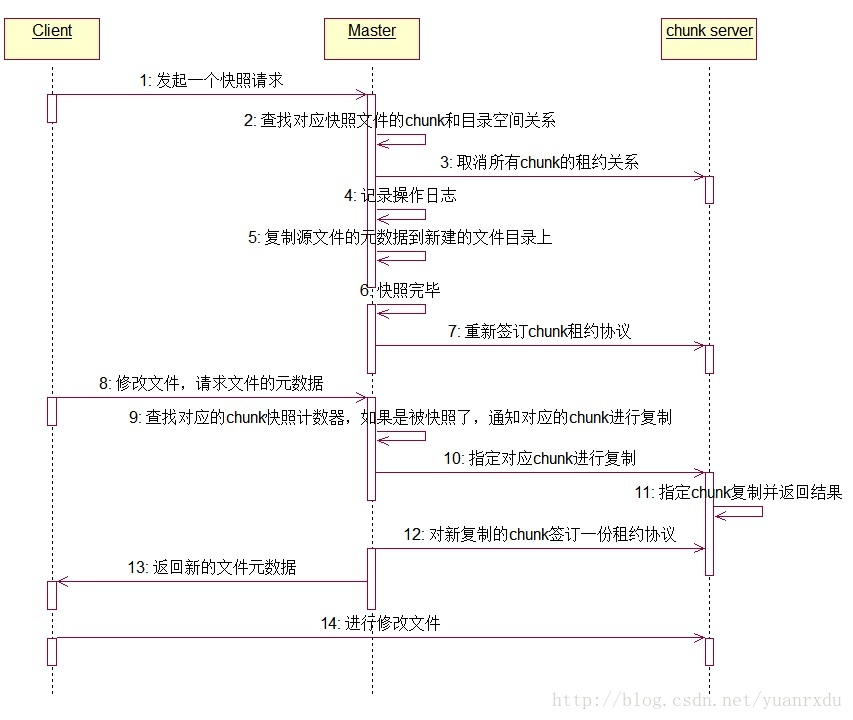
# snapshot
说实话,我没看懂块引用。。。
# 上课
consistency 会导致 low performance

不好的分布式系统:

