# Aurora
就是 cloud scale 级别的数据库。
# DURABILITY AT SCALE
# Replication and Correlated Failures
在分布式系统中,经常会遇到各种故障,并且这些故障有些是独立的,有些是相关的。一个思路来设计容错的 replicated system 就是使用 quorum-based voting protocol。
为了满足一致性,也就是能读到最新的数据,一个读操作获得的票数 Vr 与一个写操作获得的票数 Vw 的和必须是 Vr + Vw > V 。这个不等式很好理解,满足了这个不等式那么读操作必然能够读到最新的数据。同时我们也需要满足 Vw > V/2 。
但是通常为了容错的做法是:
A common approach to tolerate the loss of a single node is to replicate data to (V = 3) nodes and rely on a write quorum of 2/3 (Vw = 2) and a read quorum of 2/3 (Vr = 2).
但是作者认为这个数量不是足够的。文章中给出了一个容错设计:
每个 AZ(Availability Zone)中有两个 replicas,并且需要维持 3 个 AZ。整个系统就有 6 票,写操作需要 4 票,读操作需要 3 票。这样实现写容错就只需要一个 AZ + 一个额外节点完好,写操作只需要满足 2 个 AZ 完好就行。
# THE LOG IS THE DATABASE
# 听课

EBS 用 chain 复制的方法
# DB tutorial
只写 log record 不写 b tree,这样省时间
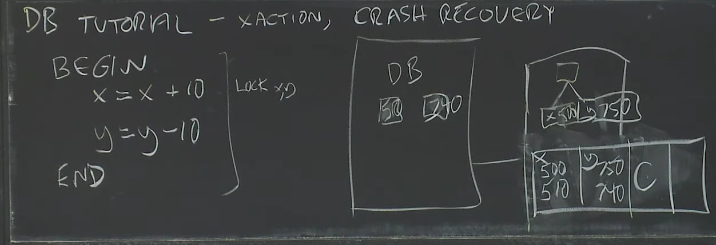
# RDS

# F.T. Goals

# Quorum
