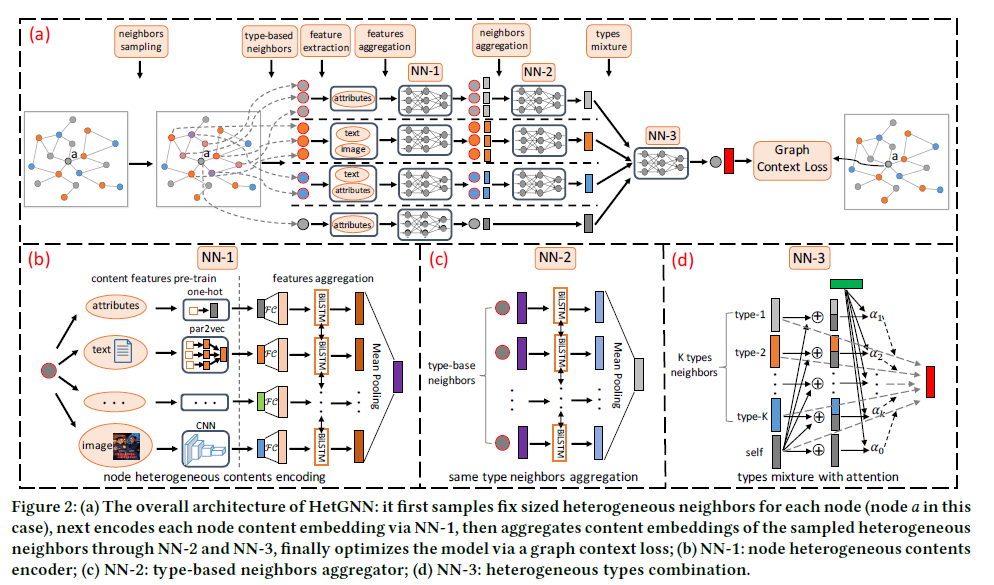
# 总览
![image-20211223195438799]()
这个算法主要分为 3 个步骤:
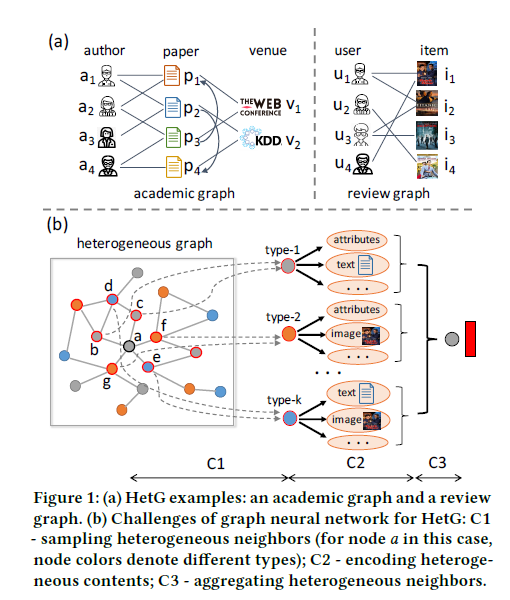
# Sampling Heterogeneous Neighbors
![image-20211223195739287]()
第一步采样得到邻居节点,作者的做法就是 random walk with restart(RWR)。这个 RWR 过程直接在异构图上进行,所以它会采样到各种节点,当节点数达到了设定的固定节点数,就停止采样。
第二步,Group nodes。就把采样得到的不同节点 group,选取每个类别下 topk 频率的节点作为邻居节点。
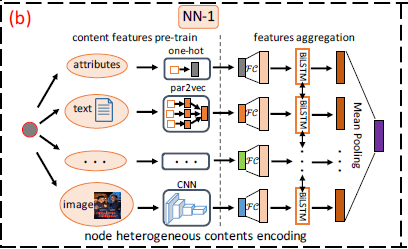
# Encoding Heterogeneous Contents
![image-20211223200126731]()
因为异构图上不同节点的 content 不同,有的节点可能是 text,有的可能是 image,有个节点既有 image 也有 text。这一步做的就是把这些 content 提取出来,并输出一个 d 维的向量。
![image-20211223200627966]()
f1(v)=∣Cv∣∑i∈Cv[LSTM{FCθx(xi)}⨁LSTM{FCθx(xi)}]
其中xi 值得是原始的 content,FC 是变换函数,这个 FC 可以是 CNN 可以是 RNN,反正就是将原本的 content 转换为向量。
LSTM 结构:
zi=σ(UzFCθx(xi)+Wz hi−1+bz)fi=σ(UfFCθx(xi)+Wf hi−1+bf)oi=σ(UoFCθx(xi)+Wo hi−1+bo)c^i=tanh(UcFCθx(xi)+Wc hi−1+bc)ci=fi∘ci−1+zi∘c^i hi=tanh(ci)∘oi
通过双向 LSTM 把 content 聚合起来,注意这一步的聚合是只聚合了 content,也就说是在单个节点上做的。
最后通过 mean pooling 输出一个 d 维向量。
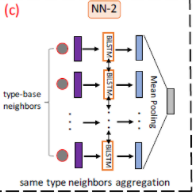
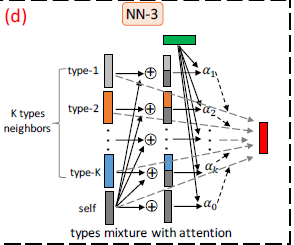
# Aggregating Heterogeneous Neighbors
第一步就是基于相同 type 的 neighbor 聚合:
![image-20211223201056370]()
同样使用一个 LSTM 进行聚合。
f2t(v)=∣Nt(v)∣∑v′∈Nt(v)[LSTM{f1(v′)}⨁LSTM{f1(v′)}]
Using different Bi-LSTMs to distinguish different node types for neighbors aggregation.
第二步,聚合不同 type 的 neighbor 信息:
不同的 embedding 对于节点的作用不同,其中f1(v) 是节点 v 经过 encoder 阶段产生的向量。其中F(v)={f1(v)∪(f2t(v),t∈OV):
Ev=fi∈F(v)∑αv,ifiαv,i=∑fj∈F(v)exp{LeakyReLU(uT[fj⊕f1(v)])}exp{LeakyReLU(uT[fi⨁f1(v)])}
![image-20211223202413189]()